In this post, I will present the blueprint for our service oriented archive. I will call it a light archive, because I hope the naming convention will create some contrast in between this system and a dark archive, which I’m going to talk about in later posts this spring.
A light archive is all about providing various users and groups with value and services, not just the raw archived data or records. Common services include search and discover features, data ingest, access and distribution of metadata, multimedia streams, downloadable copies and such. To achieve this the system itself must be like a modular ecosystem of evolving software, where each piece contributes to the system. A modular system can be upgraded and developed piece by piece, new features can be added and obsolete interfaces reworked, among other advantages. It’s not reasonable to develop the whole system in-house, and of course there is absolutely no point in reinventing the wheel. Reusing and integrating software, and contributing it back to the community creates an ecosystem that can produce high quality software. That is how we think our light archive should be built.
Solution overview
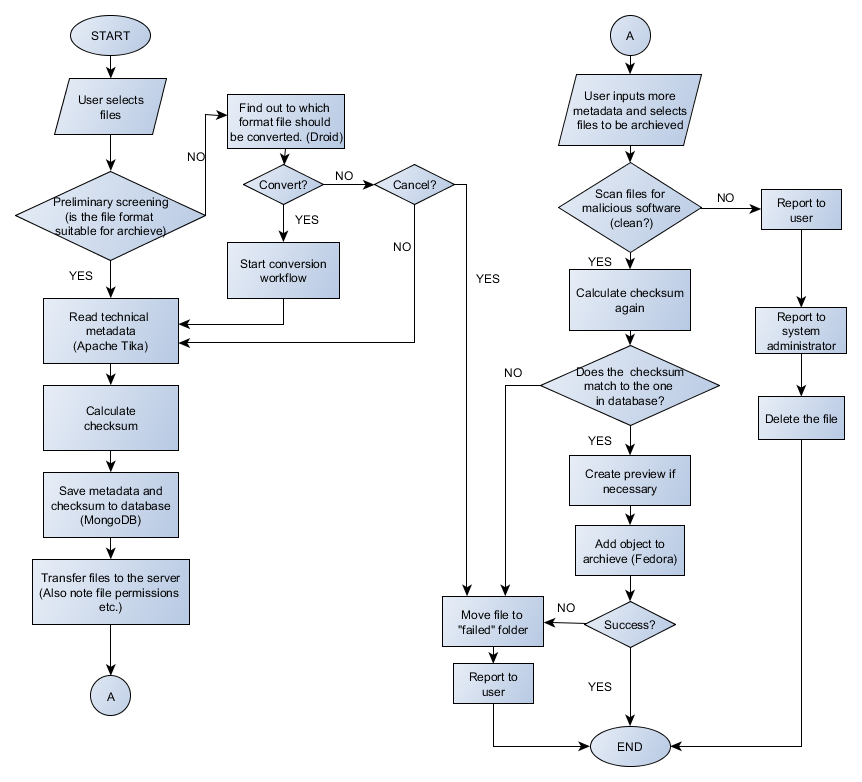
We’re building our solution in three layers. Sadly, not all of it can be made with open source. The main layers are storage, infrastructure and software. Below is a high-level overview of the solution.
A high-level overview of OSA solution.
Software is the most important layer. This includes the actual light archive software and all its components (like databases, application servers, subsystems). I will talk this in detail later on. The software layer is installed into Linux servers. Though you could most likely implement it on BSD or even on Windows based servers too. These servers can be physical or virtual. We’ve chosen virtual Centos and Ubuntu Linux distributions.
Infrastructure includes a hardware platform; physical or virtual. We built a virtual cluster with OpenNebula. There is more information on that in my previous posts. Briefly, the main idea is to have a scalable and reliable platform we can extend later based on the actual need. We can deploy our development and testing environment now and add more resources under the hood as we go. We can also relocate the virtual servers in more powerful environment without changes to the payload.
If you’re interested in the tech stuff, here are a few details. We run Centos 6.3 min as virtual hosts. It has a good support for both hardware and software. And there it is compatible with Red Hat if you require commercial support. Virtualization is based on KVM/QEMU with OpenNebula for cluster and cloud features, and Sunstone for management.
The storage technology is pretty much proprietary in our project, IBM and Oracle mostly. We need to use commercial software for the time being. One goal for the project is to find out if there is enough interest for making storage vendor independent and open source. Please let us know if you’re interested or have similar goals or a project.
Light archive architecture
As a base architecture, we use SOA (Service Oriented Architecture). It allows us to rapidly add and integrate applications to the system by using web services like REST and SOAP, and message brokers, XML or the like. Additional benefit is that we don’t need to modify the original applications and so maintain compatibility with the product. We are either not tied to just one technology. Though we have chosen Java as the main technology, nothing prevents us from adding, for instance, a Python based service and using a standard REST interface to communicate with it.
Here is the design this far. It is very basic but will be documented and planned as we go. This is an agile project, so we do prototyping and incremental development rather than design and write documents.
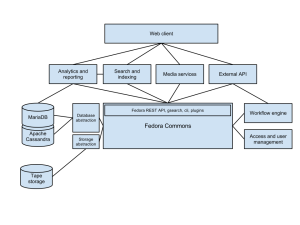
Light archive architecture.
Fedora Commons is the core software. It is an excellent mature open source project with hundreds of implementations and multiple spin-offs (e.g. Dspace). We chose Fedora because of its extendable nature and the content modeling capabilities. And the majority of the required functionality is already implemented and well tested in it. There are REST and SOAP APIs to work with in Fedora.
Data is stored in databases, in addition to OAIS packages. MariaDB is a MySQL replacement with more open source aligned future. Its upcoming release has an integration with Apache Cassandra. NoSQL is an interesting technology and we’re going to evaluate how it would work for storing archive records. The OAIS packages are going to be stored to the tape library. Previews and use copies of files are stored in a disk array. For this we need to have an abstraction layer for storage.
Search and discover features are provided by Solr, a well-known Lucene based search engine. Its features include full-text search, faceting, clustering, real-time indexing, document handling, geospatial search etc. There is a support for Solr in Fedora and most databases, including Cassandra with the Solandra project.
Analytics and reporting are a business requirement for managing the archive system. The light archive can host multiple organizations’ repositories, so the archive service provider should be able to track the usage. Of course, for the metadata, traditional big data tools could be useful for adding value to it. We’re also looking for ways to visualize the metadata, relationships and other information. Archives have huge potential for valuable and undiscovered information.
Media services, like streaming video and audio, are a must. We need to be able to let users experience the archived audiovisual data. It can be limited to identified and logged in users, paying customers, researchers or anything. But the data doesn’t provide much value if kept hidden in a dark archive. This is something that digitization companies could be interested in.
We will build an API on top of Fedora and any custom services we might develop. The API will streamline the access and add a security layer. It can also be used to publish public features online. Most likely it will be a REST API, but it’s not yet decided.
The workflow engine is an another critical component. It will handle many system processes like ingest, migration, disposal and any batch processing. Micro-services pattern is a good solution for workflows, as seen in Archivematica and DAITSS.
Finally, we need a client which consumes the web services. We will implement a web based client in this project, but it could be a desktop client or another repository as well. We have not yet decided what framework or project we’re going to use for building our client. Some Fedora projects use CMS software. Islandora for example uses Drupal as a front end. We could use our own in-house Yksa or some well-known Java platform like Liferay. We’re open to suggestions.
Next steps
Our goal is to have the working installations of all the major software during the first couple of months of this year. We need to also identify and plan the integrations.
Fedora content and service modeling is also a critical task. We’re collecting test data to use for testing and modeling work. It can also be used for testing the performance of the interfaces we’re coding. This could be a topic for a future post. As people have told me, the power and weakness of Fedora is it’s framework-like nature. It is possible and required to define what you want to do with it. While some systems dictate how to use it.
A web client is a must have for agile development. Without a user interface, we can easily get lost developing functionality without being able to test drive them. It is even more important that our partners and future users of the system can test it and tell us what they think as early as possible.
Mikko Lampi